Apprentissage par récompense ou par punition : quelles différences ?
Apprendre à rechercher le plaisir (« récompenses ») et à éviter la douleur (« punitions ») joue un rôle fondamental pour la survie de tout animal, homme inclus. C’est ce que viennent de démontrer dans un article paru dans la revue Nature Communications, des chercheurs issus du CNRS — et notamment du Groupe d'analyse et de théorie économique Lyon St-Etienne (UMR5824, CNRS / Université Lumière-Lyon 2 / Université Jean Monnet-St-Etienne / Université Claude Bernard-Lyon 1 / Ecole Normale Supérieure de Lyon) et de l’INSERM.
Malgré leur égale importance, l’apprentissage par récompense est beaucoup mieux compris que l’apprentissage par punition, d’un point de vue non seulement psychologique mais aussi neurobiologique. La principale raison à cela est que l’apprentissage par récompense est plus simple : il suffit de répéter les choix qui ont amené dans le passé à l’obtention du plaisir. En d’autres termes, il y a une association directe entre le « bon choix à faire » et le stimulus qui motive l’apprentissage (la récompense, qui a une valeur positive).
L’apprentissage par punition est cognitivement plus complexe, car cette association n’est justement pas directe. Prenons l’exemple d’un animal qui est poursuivi par un prédateur. Le bon choix consisterait à se cacher dans un trou pour fuir le prédateur et amènerait à la disparition du stimulus qui motive l’apprentissage (le prédateur, qui a une valeur négative). Par conséquent, il est difficile d’expliquer comment ce bon choix se maintient en l’absence du stimulus. Les théories courantes ont ainsi du mal à démontrer comment les hommes peuvent être aussi performants dans le domaine de la punition que dans celui de la récompense.
L’équipe de recherche a découvert récemment un algorithme permettant au cerveau humain d’apprendre à éviter des punitions aussi efficacement qu’il apprend à rechercher des récompenses. La clef de voûte de cet algorithme — appelé « RELATIVE » — consiste à calculer les résultats des actions de manière dépendante du contexte dans lequel le résultat est obtenu. Ainsi, dans l’apprentissage par punition, le résultat d’une action qui a une valeur nulle (voire légèrement négative) — se cacher dans un trou — est rapporté au contexte dans lequel ce résultat a été obtenu, qui a une valeur très négative — être poursuivi par un prédateur. Si l’on considère que la valeur de l’action est plus grande que la valeur moyenne du contexte, le bon choix acquiert ainsi une valeur « relative » positive. Il permet donc un apprentissage par récompense aussi bien que par punition.
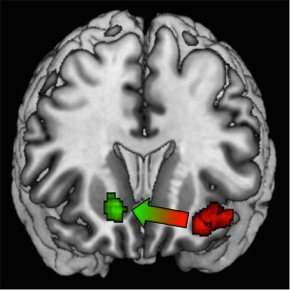
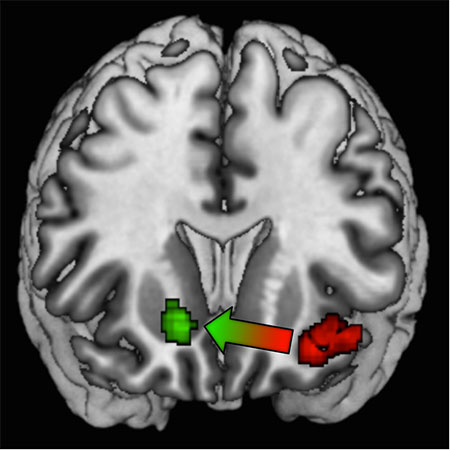
Grâce à l’imagerie par résonance magnétique cérébrale, l’équipe de recherche a aussi pu valider cet algorithme d’un point de vue neurobiologique, en montrant qu’il explique les variations d’activité cérébrale dans le cortex préfrontal médian, une zone du cerveau connue pour être impliquée dans la prise de décision. L’IRM a également permis de trancher un débat important dans la littérature : y a-t-il des systèmes ou réseaux distincts dans le cerveau pour l'apprentissage basé sur la récompense et celui basé sur la punition ? Des données expérimentales contradictoires existent, certaines suggérant que oui, d'autres que non. L’analyse démontre qu’au départ, lorsque les sujets ne semblent pas encore avoir bien appris la valeur du contexte, le système d'apprentissage basé sur la récompense (le striatum ventral) et celui basé sur la punition (l'insula) sont tous les deux activés. Puis, à mesure que la contextualisation des valeurs négatives se met en place, l’insula s'active de moins en moins, et les essais d'apprentissage dans le contexte de punition se mettent à impliquer le striatum ventral qui s'active de plus en plus.
Références :
Contextual modulation of value signals in reward and punishment learning. Stefano Palminteri, Mehdi Khamassi, Mateus Joffily, Georgio Coricelli. Nature Communications, 25 août 2015. DOI: 10.1038/ncomms9096.
En savoir plus sur le Groupe d'analyse et de théorie économique Lyon St-Etienne