Le projet ViGramm : la grammaire comme vous ne l'avez jamais vue
#ZOOM SUR...
Directeur de recherche CNRS au laboratoire Bases, Corpus, Langage (BCL, UMR7320, CNRS / Université Côte d'Azur), Diego Pescarini est un spécialiste de syntaxe comparée des langues romanes. Il porte le projet Visualizing grammars across space and time (ViGramm). Maîtresse de conférences HDR en sciences du langage à l’université de Corse Pasquale Paoli et membre du laboratoire Lieux, Identités, eSpaces et Activités (LISA, UMR6240, CNRS / Université de Corse Pasquale Paoli, Corte), Stella Retali-Medori est une dialectologue dont le domaine de recherche privilégié concerne les parlers italo-romans et plus spécialement corses. Elle est la référence du projet ViGramm à Corte. À Toulouse, le projet est coordonné par Anne Dagnac, maîtresse de conférences HDR en linguistique française et romane à l’université Toulouse - Jean Jaurès et membre du laboratoire Cognition, Langues, Langages, Ergonomie (CLLE, UMR5263, CNRS / Université Bordeaux Montaigne / Université Toulouse - Jean Jaurès), spécialiste de syntaxe, en particulier syntaxe du français et du picard, ainsi que de (micro)variation syntaxique.
Les langues font partie de notre patrimoine culturel immatériel et, à ce titre, elles sont reconnues et protégées par les conventions internationales et les lois nationales de nombreux pays. Cependant, elles restent des objets complexes qui, pris dans leur ensemble, sont difficiles à bien définir.Si l’on demandait à un échantillon de personnes de définir ce qu’est une langue, la plupart penserait probablement à des objets matérialisables et tangibles : l’ensemble des mots, dont l’expression tangible est le vocabulaire, l’écriture, un corpus de textes, etc. Cependant, il existe des aspects du langage qui sont complètement abstraits et qui échappent souvent à l’attention du discours public. La grammaire est le principal de ces aspects.
Le terme grammaire évoque de mauvais souvenirs de l'école : règles abstruses, exercices incompréhensibles, termes difficiles, etc. En fait, peu de gens croient que la grammaire peut être un sujet de recherche riche et passionnant ! Au contraire, l’équipe du projet ViGramm (Visualising Grammars across space and time) pense que les systèmes grammaticaux et, surtout, leur variation dans l’espace et dans le temps, sont un domaine d’étude fascinant, qui comporte encore un grand nombre de questions auxquelles nous n’avons pas encore répondu.
Par le terme grammaire, les linguistes entendent un système complexe de connaissances implicites qui nous permet de combiner des mots en unités plus complexes. Les linguistes ne s’intéressent donc pas aux règles grammaticales qu’on apprend à l’école, mais à la grammaire « naturelle » que les locuteurs apprennent spontanément. Pour cette raison, l’équipe de ViGramm préfère travailler sur des variétés linguistiques qui n'ont pas été standardisées ni normées par la grammaire scolaire. On peut les appeler « langues » ou « dialectes », ce dernier terme n’étant pas connoté.
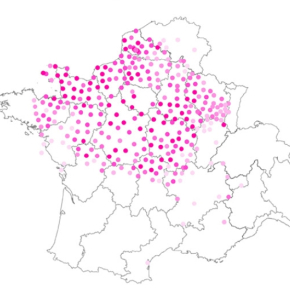
Les dialectes qui sont parlés — de plus en plus marginalement — en France ou en Italie sont un champ d'études fertile et, selon l’équipe de ViGramm, plein de surprises. Prenons comme exemple un phénomène grammatical attesté en français parlé comme la présence de la particule « que » après les pronoms interrogatifs, par exemple dans la proposition « Je ne sais pas qui (que) t’as vu ». Or, une phrase de ce type est stigmatisée par les grammaires normatives, mais les locuteurs continuent de l'utiliser, notamment dans la langue parlée. Cependant, si l’on observe les dialectes, on constate une situation beaucoup plus variée et complexe. Par exemple, il s’avère que la présence du « que » est obligatoire dans les questions directes de nombreux dialectes du nord de la France, comme le montre la figure 1[1].
les questions partielles (où que ?, quel âge que ?, comment que ?, etc.) (Dagnac 2018, source des données :
Atlas linguistique de la France, Édmont & Gilléron 1902–1910)
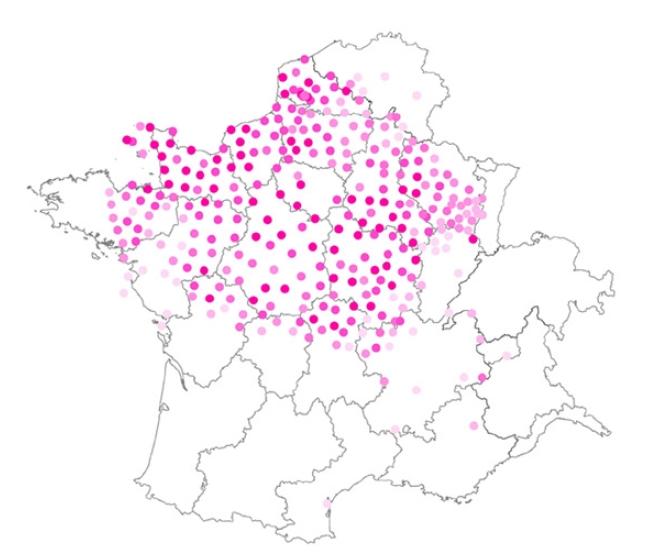
En italien, ce phénomène est pratiquement absent, tandis que les dialectes du Nord présentent obligatoirement le « que », mais avec une complication supplémentaire. Dans les dialectes du Piémont (la région la plus au nord-ouest, culturellement et géographiquement la plus proche de la France), le « que » apparaît après les pronoms interrogatifs avec une fréquence relativement élevée (voir la figure 2 : les couleurs plus foncées indiquent une plus grande incidence dans le corpus). Mais la figure 2 ne représente que les phrases principales (telles que « Qui (que) t’as vu ? »). Si toutefois nous nous concentrons sur les phrases subordonnées (comme « Je ne sais pas qui (que) t’as vu »), nous voyons qu'il existe une autre région, au nord-est, dans lequel le phénomène est attesté, mais seulement dans un contexte syntaxique plus restreint, comme le montre la figure 3.
vu ? »). Voir : Pescarini D. (in press), Doubly-Filled COMPs (which aren’t) in northern Italo-Romance, Glossa: a journal of general
linguistics. Source des sonnées : ASIt
(que) t’as vu ») (Pescarini, à paraître). Source des sonnées : ASIt
Les figures 2 et 3 montrent la propagation dans l’espace d’un phénomène grammatical isolé et plutôt simple. Ceci n'est que le point de départ de l'analyse linguistique, qui vise à comprendre comment et pourquoi ce phénomène s'est répandu dans des zones géographiques discontinues et comment ce phénomène interagit avec d'autres propriétés grammaticales. En fait, la variation grammaticale qui fait l'objet du projet ViGramm résulte de l'interaction complexe de centaines de phénomènes de ce type, qui sont à leur tour associés à d'autres propriétés grammaticales (telles que la distinction entre propositions principales et subordonnées, l’inversion du sujet, la négation, etc.).
Le but du projet ViGramm est de modéliser cette microvariation à l’aide de techniques d’analyse statistique et de visualisation de données. Les cartes des figures 1 à 3 ne sont que la première étape vers un système de représentation qui permettra de montrer — et donc de mieux comprendre — la complexité des interactions entre les variables syntaxiques afin d’aborder la variation grammaticale dans son intégralité, sans se focaliser sur des dialectes ou des phénomènes isolés.
Les données
Le projet est basé sur une méthodologie simple, mais innovante. Ces dernières années, beaucoup de projets ont été consacrés à la numérisation des principales sources de données comme les grands atlas papier, qui ont paru au début du xxe siècle, tels que l'Atlas linguistique de la France (ALF)[2], de l’Atlas Italo-Suisse (AIS), de l’Atlas Syntaxique de l’Italie (ASIt – Atlante Sintattico d’Italia), etc. Ces œuvres sont des monuments de connaissances et des sources riches en données, qui ont photographié les dialectes romans dans une phase historique où ces variétés linguistiques étaient encore vivantes.
La numérisation de ces ouvrages avait pour objectif principal la préservation d'ouvrages scientifiques qu'il n'aurait pas été possible de réimprimer en raison de leur taille et la mise à disposition en ligne des données originales sous forme numérique et annotée.
Le projet ViGramm s'inscrit dans une perspective alternative, qui ne vise pas à préserver la source, mais à la réutiliser à nouveau. Le mot clé est extraction, c'est-à-dire l'opération à travers laquelle les données des atlas sont transformées en métadonnées : des variables numériques qui représentent : a) les propriétés grammaticales présentes dans chacune des millions de phrases qui forment le corpus ; b) la provenance de chaque item ; c) les coordonnées géographiques de chaque dialecte.
Les métadonnées sont organisées en fichiers portables (.csv), qui sont stockés en libre accès sur la plateforme Nakala. Ces variables numériques se prêtent à de nombreuses formes de réutilisation : de la cartographie numérique à l'analyse statistique.
Les cartes et les supports visuels issus du projet se prêtent à des activités de diffusion visant à accroître la collaboration entre la communauté scientifique et les communautés de locuteurs. En plus des publications scientifiques, les matériaux du projet peuvent être publiés sur un site avec des fiches d'information rédigées par des experts renommés et rendues accessibles au grand public.
L’équipe
Le projet ViGramm est porté par une équipe de linguistes spécialisés dans les langues romanes, c'est-à-dire toutes les variétés linguistiques qui dérivent du latin : les langues officielles comme le français ou le roumain, mais surtout les variétés mineures (les « dialectes »).
Les trois partenaires impliqués dans le projet sont le laboratoire Bases, Corpus, Langage à Nice, le laboratoire Lieux, Identités, eSpaces et Activités à Corte et le laboratoire Cognition, Langues, Langages, Ergonomie à Toulouse).
Contact
[1] Dagnac A. 2018, SyMiLa and the Atlas linguistique de la France: A tool for the study of Gallo-Romance syntax, Glossa: a journal of general linguistics 3(1) : 85. 1–23. DOI: https://doi.org/10.5334/gjgl.543
[2] Édmont E., Gilléron J. 1902–1910, Atlas linguistique de la France, Champion.